
人类对话的本质:思维
“ 对话的最终目的是为了同步思维 ”
你是一位30出头的职场人士,每天上午9点半,都要过办公楼的旋转门,进大堂的,然后刷工牌进电梯,去到28楼,你的办公室。今天是1月6日,平淡无奇的一天。你刚进电梯,电梯里只有你一个人,正要关门的时候,有一个人匆忙挤进来。
进来的快递小哥,他进电梯时看到只有你们两人,就说了一声“你好”,然后又低头找楼层按钮了。
你很自然的回复:“你好”,然后目光转向一边。
两边都没什么话好讲——实际上,是对话双方认为彼此没有什么情况需要同步的。
人们用语言来对话,其最终的目的是为了让双方对当前场景模型(Situation model)保持同步。(大家先了解到这个概念就够了。更感兴趣的,详情请见: Toward a neural basis of interactive alignment in conversation)
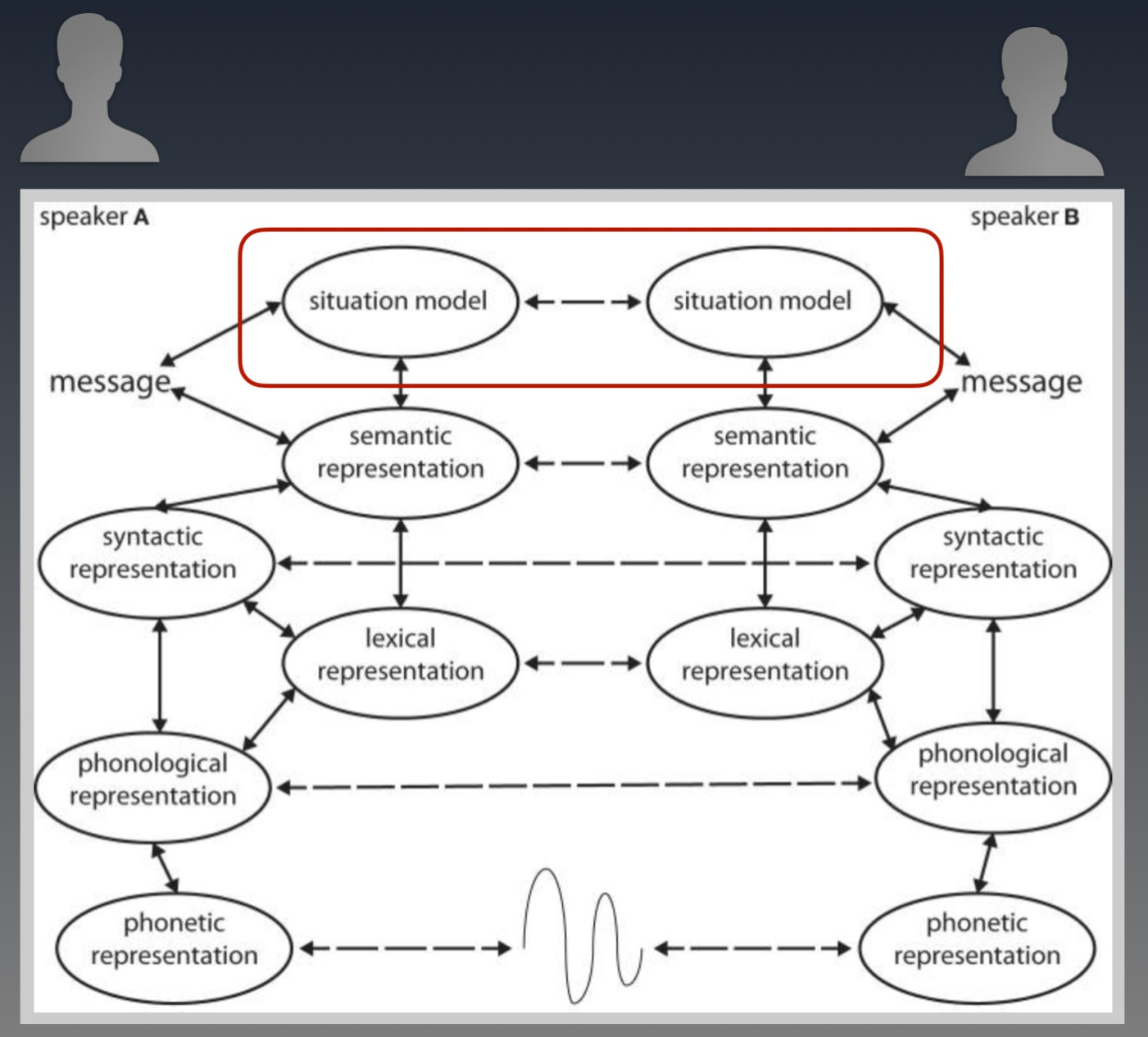
上图中,A和B两人之间发展出来所有对话,都是为了让红框中的两个“Situation model” 保持同步。Situation model 在这里可以简单理解为对事件的各方面的理解,包括Context。
不少做对话系统的朋友会认为Context是仅指“对话中的上下文”,我想要指出的是,除此以外,Context还应该包含了对话发生时人们所处的场景。这个场景模型涵盖了对话那一刻,除了明文以外的所有已被感知的信息。 比如对话发生时的天气情况,只要被人感知到了,也会被放入Context中,并影响对话内容的发展。
引用:
A: “你对这个事情怎么看?”
B: “这天看着要下雨了,咱们进去说吧”——尽管本来对话内容并没有涉及到天气。
对同一件事情,不同的人在脑海里构建的场景模型是不一样的。
(想要了解更多,可以看 Situation models in language comprehension and memory. Zwaan, R. A., & Radvansky, G. A. (1998). )
http://psycnet.apa.org/doiLanding?doi=10.1037/0033-2909.123.2.162
所以,如果匆忙进电梯来的是你的项目老板,而且假设他和你(多半都是他啦)都很关注最近的新项目进展,那么你们要开展的对话就很多了。
在电梯里,你跟他打招呼:“张总,早!”, 他会回你 “早啊,对了昨天那个…”
不待他问完,优秀如你就能猜到“张总” 大概后面要聊的内容是关于新项目的,这是因为你认为张总对这个“新项目”的理解和你不同,有同步的必要。甚至,你可以通过昨天他不在办公室,大概漏掉了这个项目的哪些部分,来推理你这个时候应该回复他关于这个项目的具体什么方面的问题。
引用:
“昨天你不在,别担心,客户那边都处理好了。打款的事情也沟通好了,30天之内搞定。”
——你看,不待张总问完,你都能很棒的回答上。这多亏了你对他的模型的判断是正确的。
一旦你对对方的情景模型判断失误,那么可能完全“没打中点上”。
引用:
“我知道,昨天晚上我回了趟公司,小李跟我说过了。我是要说昨天晚上我回来办公室的时候,
你怎么没有在加班呀?小王,你这样下去可不行啊…”
所以,人们在进行对话的过程中,并不是仅靠对方上一句话说了什么(对话中明文所包含的信息)就来决定回复什么。而这和当前的对话系统的回复机制非常不同。
“ 对话是思想从高维度向低维的投影 ”
我们假设,在另一个平行宇宙里,还是你到了办公楼。
- 今天还是1月6日,但2年前的今天,你与交往了5年的女友分手了,之后一直对她念念不忘,也没有交往新人。
- 你和往日一样,进电梯的,刚要关门的时候,匆忙进来的一个人,要关的门又打开了。就是你2年前分手的那位前女友。她进门时看到只有你们两,她抬头看了一下你,然后又低头找楼层电梯了,这时她说:“你好”。
请问你这时脑袋里是不是有很多信息汹涌而过?这时该回答什么?是不是类似“一时不知道该如何开口”的感觉?
这个感觉来自(你认为)你和她之间的情景模型有太多的不同(分手2年了),甚至你都无法判断缺少哪些信息。有太多的信息想要同步了,却被贫瘠的语言困住了。
在信息丰富的程度上,语言是贫瘠的,而思想则要丰富很多。
有人做了一个比喻:语言和思维的丰富程度相比,是冰山的一角。我认为远远不止如此:对话是思想在低维的投影。
如果是冰山,你还可以从水面上露出来的部分反推水下大概还有多大。属于维度相同,但是量不同。但是语言的问题在,只用听到文字信息,来反推讲话的人的思想,失真的情况会非常严重。

为了方便理解这个维度差异,在这儿用3D和2D来举例:思维是高维度(立体3D的形状),对话是低维度(2D的平面上的阴影)。如果咱们要从平面上的阴影的形状,来反推,上面悬着的是什么物体,就很困难了。两个阴影的形状一模一样,但是上面的3D物体,可能完全不同。
对于语言而言,阴影就像是两个 “你好”在字面上是一模一样的,但是思想里的内容却完全不同。在见面的那一瞬间,这个差异是非常大的:
引用:
你在想(圆柱):一年多不见了,她还好么?
前女友在想(球):这个人好眼熟,好像认识…
“ 挑战:用低维表达高维 ”
要用语言来描述思维有多困难?这就好比,当你试图给另一位不在现场的朋友,解释一件刚刚发生过的事情的时候,你可以做到哪种程度的还原呢?
试试用语言来描述你今天的早晨是怎么过的。
当你用文字完整描述后,我一定能找到一个事物或者某个具体的细节,它在你文字描述以外,但是却确实存在在你今天早晨那个时空里。
比如,你可能会跟朋友提到,早饭吃了一碗面;但你一定不会具体去描述面里一共有哪些调料。传递信息时,缺少了这些细节(信息),会让听众听到那碗面时,在脑海里呈现的一定不是你早上吃的“那碗面”的样子。
引用:
这就好比让你用平面上(2D)阴影的样子,来反推3D的形状。
你能做的,只是尽可能的增加描述的视角,
尽可能给听众提供不同的2D的素材,来尽量还原3D的效果。
为了解释脑中“语言”和“思想”之间的关系(与读者的情景模型进行同步),
我画了上面那张对比图,来帮助传递信息。
如果要直接用文字来精确描述,还要尽量保全信息不丢失,
那么我不得不用多得多的文字来描述细节。
(比如上面的描述中,尚未提及阴影的面积的具体大小、颜色等等细节)。
这还只是对客观事物的描述。当人在试图描述更情绪化的主观感受时,则更难用具体的文字来表达。
比如,当你看到Angelina Jordan这样的小女生,却能唱出 I put a spell on you 这样的歌的时候,请尝试用语言精确描述你的主观感受。是不是很难?能讲出来话,都是类似“鹅妹子嘤”这类的?这些文字能代表你脑中的感受的多少部分?1%?
希望此时,你能更理解所谓 “语言是贫瘠的,而思维则要丰富很多”。
那么,既然语言在传递信息时丢失了那么多信息,人们为什么理解起来,好像没有遇到太大的问题?
“ 为什么人们的对话是轻松的?”
假设有一种方式,可以把此刻你脑中的感受,以完全不失真的效果传递给另一个人。这种信息的传递和上面用文字进行描述相比,丰富程度会有多大差异?
可惜,我们没有这种工具。我们最主要的交流工具,就是语言,靠着对话,来试图让对方了解自己的处境。
那么,既然语言这么不精准,又充满逻辑上的漏洞,信息量又不够,那么人怎么能理解,还以此为基础,建立起来了整个文明?
比如,在一个餐厅里,当服务员说 “火腿三明治要买单了”,我们都能知道这和“20号桌要买单了”指代的是同样的事情 (Nuberg,1978)。是什么让字面上那么大差异的表达,也能有效传递信息?
人能通过对话,有效理解语言,靠的是解读能力——更具体的点,靠的是对话双方的共识和基于共识的推理能力。
当人接收到低维的语言之后,会结合引用常识、自身的世界模型(后详),来重新构建一个思维中的模型,对应这个语言所代表的含义。这并不是什么新观点,大家熟悉的开复老师,在1991年在苹果搞语音识别的时候,就在采访里科普,“人类利用常识来帮助理解语音”。 人类利用常识来帮助理解语音
当对话的双方认为对一件事情的理解是一样的,或者非常接近的时候,他们就不用再讲。需要沟通的,是那些(彼此认为)不一样的部分。
引用
当你听到“苹果”两个字的时候,你过去建立过的苹果这个模型的各个维度,
就被引用出来,包括可能是绿或红色的、味道的甜、大概拳头大小等等。
如果你听到对方说“蓝色的苹果”时,这和你过去建立的关于苹果的模型不同(颜色)。
思维就会产生一个提醒,促使你想要去同步或者更新这个模型,“苹果为什么是蓝色的?”
例子1,如果你的世界模型里已经包含了“华农兄弟” (你看过并了解他们的故事),你会发现我在Part 2最开始的例子,藏了一个梗(做成叫花鸡)。但因为“华农兄弟”并不是大多数人都知道的常识,而是我与特定人群的共识,所以你看到这句话时,获得的信息就比其人多。而不了解这个梗的人,看到那里时就不会接收到这个额外的信息,反而会觉得这个表达好像有点点奇怪。
例子2,创投圈的朋友应该都有听说过 Elevator pitch,就是30秒,把你要做什么事情讲清楚。通常的案例诸如:“我们是餐饮界的Uber”,或者说“我们是办公室版的Airbnb”。这个典型结构是“XX版的YY”,要让这句话起到效果,前提条件是XX和YY两个概念在发生对话之前,已经纳入到听众的模型里面去了。如果我给别人说,我是“对话智能行业的麦肯锡”,要能让对方理解,对方就得既了解对话智能是什么,又了解麦肯锡是什么。
“ 基于世界模型的推理 ”
场景模型是基于某一次对话的,对话不同,场景模型也不同;而世界模型则是基于一个人的,相对而言长期不变。
对世界的感知,包括声音、视觉、嗅觉、触觉等感官反馈,有助于人们对世界建立起一个物理上的认识。对常识的理解,包括各种现象和规律的感知,在帮助人们生成一个更完整的模型:世界模型。
无论精准、或者对错,每一个人的世界模型都不完全一样,有可能是观察到的信息不同,也有可能是推理能力不一样。世界模型影响的是人的思维本身,继而影响思维在低维的投影:对话。
让我们从一个例子开始:假设现在咱们一起来做一个不那么智障的助理。我们希望这个助理能够推荐餐厅酒吧什么的,来应付下面这样的需求:
我想喝点东西
当用户说:“我想喝点东西”的时候,系统该怎么回答这句话?经过Part 2,我相信大家都了解,我们可以把它训练成为一个意图“找喝东西的店”,然后把周围的店检索出来,然后回复这句话给他:“在你附近找到这些选择”。
恭喜,咱们已经达到Siri的水平啦!
但是,刚刚我们开头就说了,要做不那么智障的助理。这个“喝东西的店”是奶茶点还是咖啡店?还是全部都给他?
嗯,这就涉及到了推理。我们来手动模拟一个。假设我们有用户的Profile数据,把这个用上:如果他的偏好中最爱的饮品是咖啡,就给他推荐咖啡店。
这样一来,我们就可以更“个性化”的给他回复了:“在你附近找到这些咖啡店”。
这个时候,咱们的AI已经达到了不少“智能系统”最喜欢鼓吹的个性化概念——“千人千面”啦!
然后我们来看这个概念有多蠢。
一个人喜欢喝咖啡,那么他一辈子的任意时候就都要喝咖啡么?人是怎么处理这个问题的呢?如果用户是在下午1点这么问,这么回他还好;如果是在晚上11点呢?我们还要给他推荐咖啡店么?还是应该给他推荐一个酒吧?
或者,除此之外,如果今天是他的生日,那么我们是不是该给他点不同的东西?或者,今天是圣诞节,该不该给他推荐热巧克力?
你看,时间是一个维度,在这个维度上的不同值都在影响给用户回复什么不同的话。
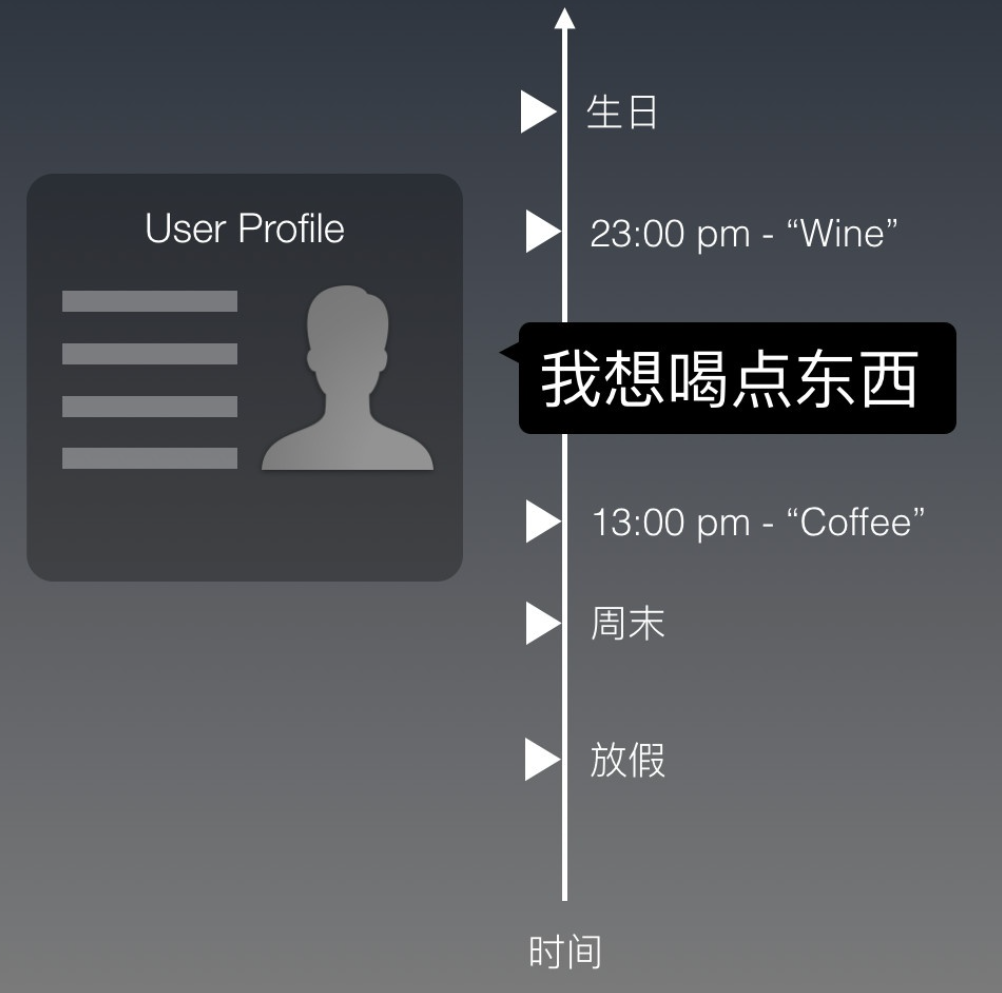
时间和用户的Profile不同的是:
1.时间这个维度上的值有无限多;
2.每个刻度还都不一样。比如虽然生日是同一个日期,但是过生日的次数却不重复;
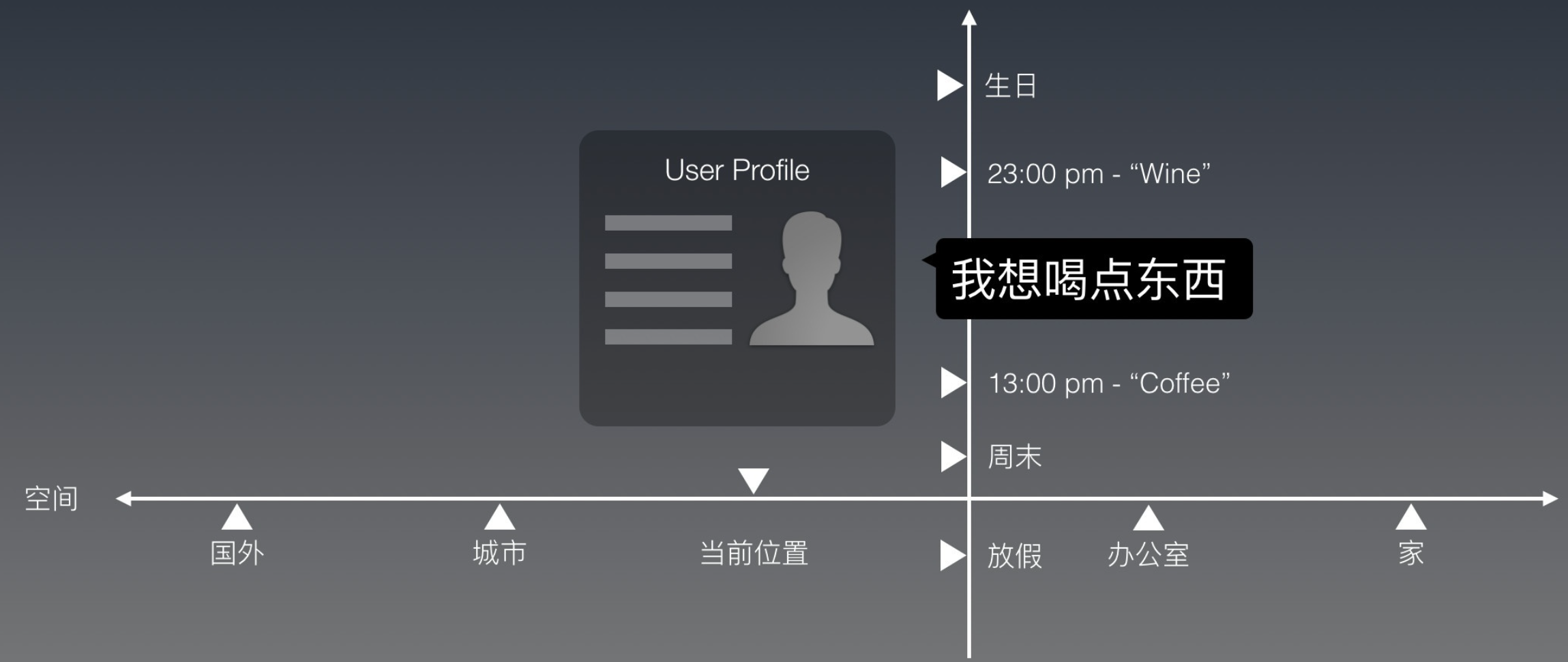
除了时间这个维度以外,还有空间。
于是我们把空间这个维度叠加(到时间)上去。你会发现,如果用户在周末的家里问这个问题(可能想叫奶茶外卖到家?),和他在上班时间的办公室里问这个问题(可能想出去走走换换思路),咱们给他的回复也应该不同。
光是时空这两个维度,就有无穷多的组合,用"if then"的逻辑也没法全部手动写完。我们造机器人的工具,到这个需求,就开始捉襟见肘了。
何况时间和空间,只是世界模型当中最显而易见的两个维度。还有更多的,更抽象的维度存在,并且直接影响与用户的对话。比如,人物之间的关系;人物的经历;天气的变化;人和地理位置的关系(是经常来出差、是当地土著、是第一次来旅游)等等等等。咱们聊到这里,感觉还在聊对话系统么?是不是感觉有点像在聊推荐系统?
要想效果更好,这些维度的因素都要叠加在一起进行因果推理,然后把结果给用户。
至此,影响人们对话的,光是信息(还不含推理)至少就有这三部分:明文(含上下文)+ 场景模型(Context)+ 世界模型。
普通人都能毫不费力地完成这个工作。但是深度学习只能处理基于明文的信息。对于场景模型和世界模型的感知、生成、基于模型的推理,深度学习统统无能为力。
根据世界模型进行推理的效果,不仅仅体现上在对话上,还能应用在所有现在成为AI的项目上,比如自动驾驶。
经过大量训练的自动驾驶汽车,在遇到偶发状况时,就没有足够的训练素材了。比如,突然出现在路上的婴儿车和突然滚到路上的垃圾桶,都会被视为障碍物,但是刹不住车的情况下,一定要撞一个的时候,撞哪一个?
又比如,对侯世达(Douglas Hofstardler )而言,“驾驶”意味着当要赶着去一个地方的时候,要选择超速还是不超速;要从堵车的高速下来,还是在高速上慢慢跟着车流走...这些决策都是驾驶的一部分。他说:
世界上各方面的事情都在影响着“驾驶”这件事的本质。
“ 人脑有两套系统:系统1 和系统2 ”
关于 “系统1和系统2”的详情,请阅读 Thinking, Fast and Slow, by Daniel Kahneman,一本非常好的书,对人的认知工作是如何展开的进行了深入的分析。在这儿,我给还不了解的朋友介绍一下,以辅助本文前后的观点。
心理学家认为,人思考和认知工作分成了两个系统来处理:
1.系统1是快思考:无意识、快速、不怎么费脑力、无需推理
2.系统2是慢思考:需要调动注意力、过程更慢、费脑力、需要推理
系统1先上,遇到搞不定的事情,系统2会出面解决。
系统1做的事情包括: 判断两个物体的远近、追溯声音的来源、完形填空 ( "我爱___ " )等等。
另外,在系统1所设定的世界里,猫不会像狗一样汪汪叫。若事物违反了系统1所设定的世界模型,系统2也会被激活。
“ 对话智能的核心价值:在内容,不在交互 ”
“ 对话智能解决重复思考 ”
2025-02-01 20:05:36 Saturday
Comments NOTHING